
What Is Prompt Engineering?
Prompt engineering is the discipline of crafting precise inputs—known as “prompts”—to steer large language models (LLMs) toward generating high-quality, contextually relevant output. Unlike traditional programming, prompt engineering relies on natural language instructions or examples rather than lines of code. Because LLMs are trained on vast corpora of text, they can interpret and generate human-like responses in a wide range of domains. The engineering comes into play by designing prompts that guide these models to reason more effectively, reduce unwanted biases, and maintain coherence across lengthy or complex tasks.
In practice, prompt engineering is where linguistics, machine learning, and user experience intersect. By shaping the exact wording, structure, and style of the input, practitioners can significantly influence the quality of the output. OpenAI’s GPT-3 offered an early glimpse into the potential of prompt-based interactions, showcasing few-shot learning skills that allowed it to tackle new tasks from minimal examples. Since then, prompt engineering has rapidly matured from an experimental approach into a recognized specialization, influencing everything from commercial AI applications to cutting-edge academic research.

Why Prompt Engineering Matters Today
The significance of prompt engineering stems from the broader transformation of AI. As LLMs become integral to customer service, content generation, and complex decision support, businesses and researchers alike see that a well-crafted prompt can deliver safer, more reliable, and more accurate model outputs. The difference between a poorly designed prompt and a well-designed one is often the difference between a confused, irrelevant response and an answer that solves real-world problems.
But effectiveness is just one facet. Prompt engineering also addresses concerns around bias, misuse, and factual inaccuracies. By embedding the right context, constraints, or chain-of-thought instructions, prompt engineers can mitigate some of the ethical and technical pitfalls that arise when working with large, opaque AI models. In short, the discipline is about harnessing the power of these models responsibly, optimizing them for insight instead of error.
Prompt Engineering: Historical and Technical Context
Despite its current popularity, the idea of prompting large models isn’t entirely new. Early natural language processing (NLP) systems in the 1970s used rudimentary “pattern matching” prompts, but these were a far cry from the sophisticated prompts we see today. Recent breakthroughs in transformer-based architectures—particularly those that scale well with massive training datasets—ushered in a new era of AI capabilities. Models like GPT-3, PaLM, and others rely on billions or trillions of parameters, creating a capacity for nuanced language understanding unthinkable just a decade ago.
By 2020, OpenAI researchers demonstrated a phenomenon called “few-shot learning” in LLMs. With minimal instruction and limited examples, these models solved diverse tasks—everything from translation to summarization. This revelation underscored that, even without traditional fine-tuning, LLMs could adapt to new domains if the “prompt” offered enough context and structure. Soon after, Google researchers in 2022 introduced the concept of “Chain-of-Thought Prompting,” which instructs models to reveal intermediate reasoning steps. These findings provided the technical bedrock for a more systematic approach to designing prompts.
Today, prompt engineering merges insights from psychology, human-computer interaction, and computational linguistics. It not only addresses how to coax the best output from existing models but also shapes new directions in model interpretability, ethical AI, and advanced research on how language models represent and manipulate knowledge.
Core Methods and Strategies for Prompt Engineering
A key aspect of prompt engineering is understanding various methods that can elicit better performance, clarity, or reliability from large language models. Below, we explore three fundamental strategies: Zero-Shot Prompting, Few-Shot Prompting, and Chain-of-Thought Prompting.
Zero-Shot Prompting
With zero-shot prompting, the model is given an instruction or question without any specific examples. For instance, you might simply ask, “Explain how photosynthesis works for a middle-school science project.” The model relies on its general knowledge—amassed during pretraining—and attempts to comply directly with the request.
Zero-shot prompting is efficient and quick, but it often provides less control over the model’s direction. If the user’s query is ambiguous or the model’s internal reasoning is suboptimal, responses can vary in quality. However, zero-shot prompting is invaluable for tasks that are relatively straightforward and do not require a high degree of nuance or customization.
Few-shot prompting supplies the model with a handful of examples before the main query. For a text-classification task, you might include labeled examples—“Positive: ‘I loved this movie!’ / Negative: ‘The food was terrible!’”—and then ask the model to classify a new sentence. This approach helps the model align more closely with the specific style, format, or criteria you need.
Few-shot prompts can significantly boost performance, especially when the model is tackling specialized domains or tasks with particular constraints. By guiding the model with explicit examples, you reduce ambiguity and potential error. This method became a focal point of research after GPT-3’s release, showing that examples can serve almost as a form of real-time “mini-finetuning” for the model’s behavior.
Chain-of-Thought Prompting
Introduced in Wei et al. (2022), chain-of-thought (CoT) prompting encourages the model to display its step-by-step reasoning. Instead of presenting the final answer outright, the prompt instructs the model to reason aloud, enumerating the logical or interpretive steps. The underlying idea is that by making the reasoning more explicit, you improve both the transparency and accuracy of the result.
Below is a simple flowchart illustrating how chain-of-thought prompting helps break down a question into smaller reasoning steps:
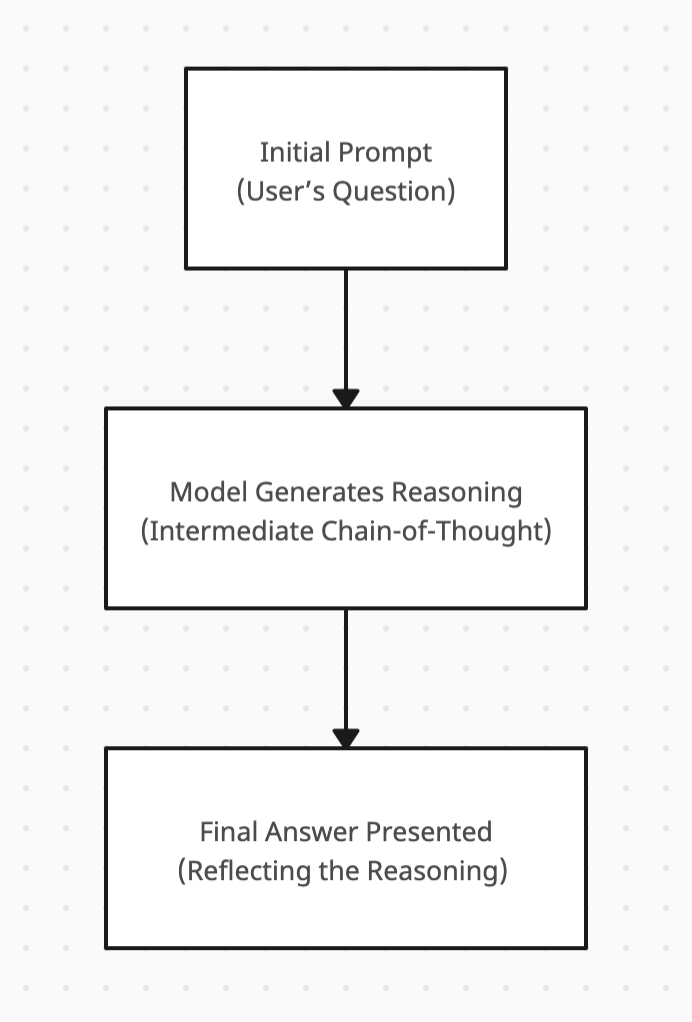
This structured reasoning proves especially powerful for tasks like mathematical problem-solving, multi-step logical deductions, or detailed text analysis, where the path to the answer is often as important as the answer itself.
Side-by-Side Comparison: Zero-Shot Vs. Few-Shot Vs. Chain-of-Thought (CoT)
Empirical Benchmarks and Observations
When researchers first studied prompt engineering in large language models, they used both internal analyses and standardized benchmarks. Popular datasets, such as SQuAD for question answering or GLUE for language understanding, helped measure how effectively different prompting methods improve model performance.
Incorporating Short-Form Factuality with SimpleQA
Recently, in 2024, researchers from OpenAI, introduced SimpleQA, a benchmark designed to evaluate how well large language models handle short, fact-seeking questions with a single indisputable answer. Compared to general-purpose QA datasets, SimpleQA forces models to “know what they know” by penalizing half-true guesses and incentivizing them to either answer correctly or refrain from guessing when uncertain.
In practice, SimpleQA underscores the role of precise prompts for factual queries: the more explicitly we ask for a single correct fact—and allow for refusal if unsure—the less likely the model is to hallucinate or produce overconfident errors. This aligns with broader findings that carefully crafted prompts, especially those that encourage the model to admit uncertainty, can reduce error rates by a noticeable margin.
Broader Empirical Evidence of Prompting Gains
According to OpenAI’s 2020 paper on language model and few-shot leaders, providing even two or three carefully designed examples in a prompt can raise accuracy on certain benchmarks by more than 10% compared to zero-shot. Google further demonstrated that chain-of-thought prompting can greatly enhance performance on multi-step reasoning tasks, like arithmetic word problems, because it makes intermediate reasoning steps explicit.
Beyond academic benchmarks, enterprise testing also confirms that structured prompting can reduce error rates and increase user satisfaction. While some reports remain proprietary, anecdotally we see that companies adopting advanced prompting strategies often report fewer irrelevant responses from AI-driven customer service bots, and more consistent content generation in marketing workflows.
Pro Tips for Crafting Effective Prompts
Clarity is Key
Use straightforward language and specific instructions.
Set the Context
Provide concise background information so the model grasps the scenario.
Experiment Iteratively
Tweak prompts step-by-step, observing changes in output quality.
Mind Word Limits
Extremely long or complex prompts can confuse rather than clarify.
Challenges in Prompt Engineering
Despite its promise, prompt engineering is not a silver bullet. Ambiguity in natural language often remains a challenge, causing models to interpret the same phrase in multiple ways. Additionally, the length of the prompt can become unwieldy if one tries to address every potential ambiguity up front.
Best Practices for Reducing Hallucinations
Although bias is one concern, another persistent issue is “hallucinations,” where the model confidently provides incorrect factual information. The SimpleQA framework suggests a practical strategy: encourage the model to return a “not attempted” response if it cannot confidently pinpoint a single correct fact. In prompt-engineering terms, this might entail adding instructions such as, “If you are not certain of the answer, please indicate that you do not know.” This directive helps the model distinguish between correctable uncertainty and pure guesswork.
By prompting the model to weigh its confidence, developers can reduce the frequency of spurious or half-true answers—an especially valuable tactic in fields like medical QA or legal document processing, where guesswork is risky. Over time, such cautionary prompts can be refined further, aligning the system’s willingness to answer with the actual likelihood of correctness.
Managing Bias and Resource Constraints
Another major challenge is bias control. LLMs learn from huge datasets that inevitably contain social and cultural biases. If a prompt inadvertently triggers these biases, the resulting output might be skewed or harmful. While techniques like few-shot or chain-of-thought prompting can reduce the appearance of biased content, they are not guaranteed to eliminate it.
Finally, prompt engineering is still resource-intensive: large models consume significant computational power, making iterative experimentation costly for organizations without substantial AI budgets. Those in smaller teams or with limited computational resources must often rely on best-practice templates or open-source communities to guide their prompts, rather than conducting exhaustive trials on their own.

Practical Applications and Industry Use Cases
Prompt engineering’s influence is visible across a rapidly growing range of real-world applications, where carefully designed prompts can drastically improve output clarity, reduce errors, and align AI behavior with specific organizational goals. From automating customer support workflows to generating creative marketing content, businesses across diverse sectors are discovering that the right prompts can unlock unprecedented levels of efficiency and customization. Below, we explore several notable domains in which prompt engineering is proving indispensable:
Customer Support Automation
By using few-shot and chain-of-thought prompts, AI-driven chatbots can more reliably interpret nuanced customer inquiries. For instance, a telecommunications provider might provide examples of troubleshooting steps and then instruct the model to walk through logical sequences when diagnosing a connection issue. This structured approach can reduce ambiguous answers and lower the load on human support teams.
Code Generation and Review
Developers leverage large models to generate snippets of code or perform automated code reviews. With a robust few-shot prompt, the AI “learns” the style guidelines and architectural patterns of a specific project. It can then propose relevant solutions or spot potential errors in new submissions. This not only speeds up development but also fosters consistency across large engineering teams.
Creative Content and Marketing
Marketers use prompting to brainstorm ad copy, social media posts, or creative brand narratives. A few guiding examples might provide the tone, length, or voice desired, while a chain-of-thought approach encourages the model to rationalize the angle or story arc. The result is content that’s both relevant and aligned with the brand’s style guidelines.
Education and Training
In educational technologies, prompt engineering helps craft adaptive quizzes and explanatory material. For a language learning app, well-designed prompts can generate relevant dialogues, vocabulary lessons, and follow-up questions that respond dynamically to a learner’s progress.
Future Directions and Emerging Frontiers
As large language models continue to scale in both complexity and impact, prompt engineering stands at the intersection of groundbreaking research and practical innovation. From leveraging multimodal inputs to exploring auto-refinement where models enhance their own prompts, we’re witnessing a shift toward more adaptive and context-rich AI interactions. Yet these new possibilities also bring an increased focus on safety, oversight, and the broader societal footprint of AI-driven decisions.
Ethical Dimensions and Responsible Use
As large language models become integral to critical domains—from healthcare triage to educational tutoring—questions about fairness, bias, and accountability loom larger than ever. Researchers have shown that even advanced systems can inadvertently reproduce harmful societal stereotypes present in their training data (Bender et al., 2021; Deepmind/Weidinger et al., 2022). While strategies like filtering or post-processing can mitigate overtly problematic outputs, truly responsible prompting relies on human oversight. Engineers and product teams must continuously audit the model’s performance, refining prompts whenever discriminatory or misleading content surfaces. Meanwhile, regulatory bodies in various regions have started drafting guidelines that demand clearer disclosure of AI-generated content, shifting prompt engineering from a purely technical craft to one that must also prioritize user safety and transparency.
Multimodal Possibilities
Although prompt engineering is often considered a text-focused discipline, recent research on foundation models has widened the conversation to include images, audio, and even video (Bommasani et al., 2021; Radford et al., 2021). In these scenarios, prompts might reference visual or auditory cues alongside standard textual instructions—think of an industrial engineer presenting a photograph of a defective component with a query, “Pinpoint likely points of failure.” The model must merge visual interpretation with language comprehension to generate actionable insights. This broadens the scope of prompt engineering but also introduces new complexities, such as aligning multi-format data under a single directive. For practitioners, preparing for these multimodal applications involves developing robust prompt templates that specify how images or audio correlate with textual queries.
Short-Form Factuality as a Stepping Stone
While this article has focused on prompt-engineering tactics for text, SimpleQA highlights an emerging priority: calibrating models to only respond when they can back their answers with high certainty. This principle extends beyond text-based queries; as multimodal models mature, the same fact-checking mindset will become crucial for image-based or audio-based prompts. By making “refusal to guess” a valid design choice, we encourage safer AI interactions—particularly in high-stakes industries like finance, healthcare, and public policy.
As these benchmarks evolve, so do the responsibilities of prompt engineers. Establishing more precise instructions, auditing models for confabulations, and integrating calibration metrics at every step will likely define the next wave of best practices. In this sense, short-form factual accuracy serves as a practical foundation for tackling the even broader challenges of multi-turn dialogues and cross-format data fusion.
Meta-Prompting and Automated Refinement
Another frontier is meta-prompting—where the model learns to optimize its own prompts in real time. While still experimental, early conceptual work suggests that such automated systems might cut down on the iterative back-and-forth inherent in prompt design. However, they also raise questions about transparency and ethical guardrails: if the model is both subject and author of its instructions, who is ultimately accountable for mistakes or biases? Ongoing research points to hybrid approaches that combine human oversight with semi-automated refinement to strike a balance between efficiency and reliability (Weidinger et al., 2022).
Practical Steps Forward
Teams looking to apply prompt engineering immediately can begin with zero-shot or few-shot examples, especially if they aim to establish quick proof-of-concept results. Tracking metrics—like user satisfaction, error rates, or domain-specific benchmarks—helps isolate which prompts drive meaningful improvements. Creating a shared “prompt library” can also unify best practices across departments, reducing guesswork and duplication. Over time, organizations may explore chain-of-thought prompts for complex tasks that benefit from transparent reasoning. By adopting this iterative, data-driven methodology, professionals lay the groundwork for an adaptable prompt engineering strategy that evolves as LLM capabilities—and regulatory frameworks—expand.
Concluding Thoughts
Prompt engineering represents a pivotal shift in how we interact with AI—no longer confined to black-box model behavior, we now sculpt the model’s outputs via meticulously crafted instructions. This dynamic interplay between human creativity and machine intelligence has already yielded tangible gains: from more intuitive customer interactions to improved diagnostic tools and specialized content generation. Yet with progress come new responsibilities. Scholars emphasize the importance of integrating ethical guardrails early in the design process (Bender et al.; Weidinger et al.), and the push toward multimodal capabilities signals that future prompts may need to reference images, videos, or audio streams as fluidly as text (Bommasani et al.; Radford et al.).
Organizations that master this evolving discipline stand to unlock competitive advantages through more responsive, user-centric AI solutions. Researchers, meanwhile, have only begun to scratch the surface of how prompts can be optimized—especially once models learn to refine themselves. By recognizing prompt engineering as both a practical technique and an ethical responsibility, we ensure that these powerful systems advance in alignment with broader societal values. In doing so, we take a crucial step toward shaping the next generation of AI, one prompt at a time.
Further Resources
OpenAI developer documentation
https://platform.openai.com/docs
A core reference for working with OpenAI’s language models. Includes usage guidelines, API references, and sample code for prompt engineering.
OpenAI Cookbook
https://github.com/openai/openai-cookbook
An extensive repository of example notebooks, detailing best practices in prompt design, model experimentation, and real-world application setups.
Hugging Face transformers
https://huggingface.co/docs/transformers
While focused on open-source language models like GPT-2, T5, and BERT, this library and documentation suite includes tutorials on prompt-based fine-tuning, tokenization, and community-driven best practices.
LangChain
https://github.com/hwchase17/langchain
A popular framework for building advanced LLM-powered applications with features like prompt templates, chaining prompts together, and integrating external knowledge sources.
Microsoft guidance
https://github.com/microsoft/guidance
An open-source library that offers a specialized syntax to manage prompting and chaining with LLMs. Helpful for large-scale prompt experimentation and structured flow control.
Prompt engineering community resources
https://github.com/dair-ai/Prompt-Engineering-Guide
A curated guide and collection of tutorials, papers, and articles dedicated to prompt engineering best practices, examples, and emerging research.
Github-based guidance language for controlling large language models
https://github.com/guidance-ai/guidance
An open-source library for structuring and constraining LLM output—using techniques like regex, context-free grammar rules, and integrated tool calls—to create more reliable, efficient, and stateful prompt-driven workflows.
Github-based curated list of resources and tools for LLM prompt engineering
https://github.com/snwfdhmp/awesome-gpt-prompt-engineering
A curated compilation of tutorials, tools, and best practices around GPT prompt engineering, offering everything from zero/few-shot strategies to specialized community resources.





